In deze derde blog over het bereiken van een andere mindset als je je businesstools wilt veranderen van Excel naar Power BI. In de eerste blog schreef ik over de definitie van een genormaliseerde tabel en in de tweede blog schreef ik hoe je een genormaliseerde tabel maakt. In deze blog wil ik het hebben […]

In deze derde blog over het bereiken van een andere mindset als je je businesstools wilt veranderen van Excel naar Power BI. In de eerste blog schreef ik over de definitie van een genormaliseerde tabel en in de tweede blog schreef ik hoe je een genormaliseerde tabel maakt. In deze blog wil ik het hebben over waar je transformaties op een genormaliseerde tabel kunt opslaan, gebruiken en uitvoeren.
Er zijn twee opties om uw gegevens uit een database naar Power BI te krijgen. Via een directe verbinding of door tussenbestanden te gebruiken om uw tabellen op te slaan. Veruit de beste optie is de eerste: maak een directe verbinding met een database. Binnen Power BI en Excel Power Query zijn allerlei connectoren beschikbaar voor alle soorten databases.
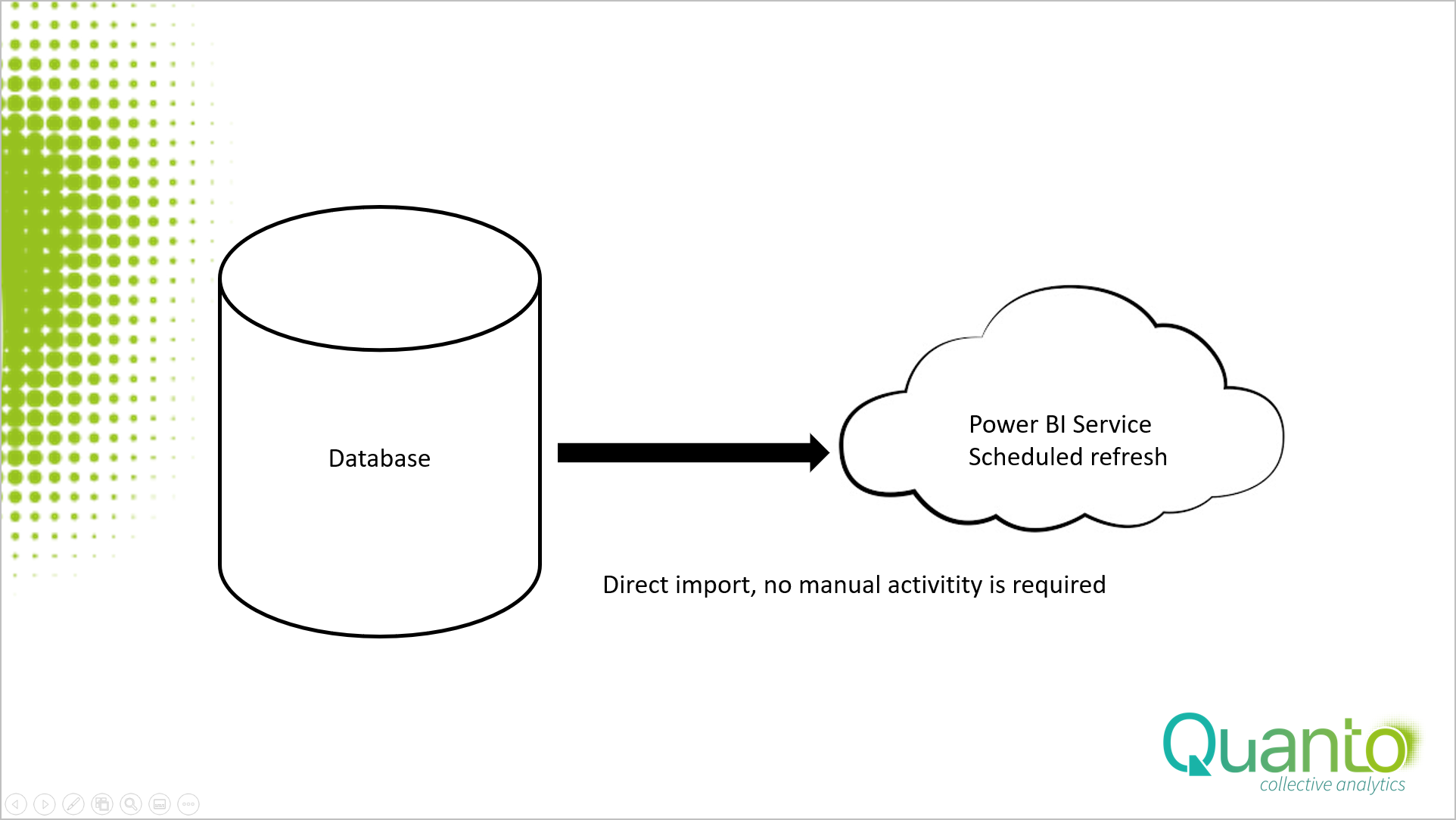
Voeg gewoon de juiste gateway binnen de service toe, schakel de geplande vernieuwingsoptie in en u hoeft zich nooit meer zorgen te maken over het bijwerken van uw model. Met een Power BI Pro licentie ververs je de data en het model tot 8 keer per dag. Vergelijk dit tarief met uw standaard Excel “eens per maand” bijgewerkte bedrijfsrapporten en u vindt de voordelen.
Maar wat als je die luxe niet hebt? Wat als u niet de toestemming heeft om rechtstreeks verbinding te maken met uw databases en u alleen tabellen in een CSV- of Excel-bestand kunt downloaden? Overweeg de tweede optie en maak gebruik van tussentabellen.

Uw opties in dit scenario zijn afhankelijk van de interface van de databasehost. Er zijn hosts waarmee een schema de tabelgegevens automatisch via een sjabloon naar een bestand kan pushen. In dat geval heb je geluk. Je hoeft alleen maar de push- en verversingsmomenten te synchroniseren: eerst moet de push behaald worden. Nadat het bestand is gemaakt, moet de geplande Power BI-vernieuwingsimport worden geactiveerd om uw Power BI-rapporten bij te werken. Omdat alle acties automatisch worden uitgevoerd, creëer je een cyclus die -net als de eerste optie- automatisch verloopt. Een van de beste praktijken is om één centrale locatie te creëren met een set mappen voor uw periodiek gedownloade gegevens, waar alle noodzakelijke tussentabellen worden geplaatst. Het wordt afgeraden om de tussentabellen op uw schijven kapot te maken.
Als er iets in dit proces mislukt, kan het even duren voordat u de fout kent. Als de push bijvoorbeeld wordt uitgesteld, worden de bijgewerkte gegevens mogelijk niet doorgegeven aan het model. Dit doet nog meer pijn als sommige tabellen worden vernieuwd en andere niet. Bereken dus zorgvuldig de push- en refresh-momenten. En vergeet niet de (e-mail)meldingen bij push- en verversingsfouten in te schakelen. Dat klinkt voor de hand liggend, maar ik ken situaties waarin het een tijdje duurde voordat een herhaaldelijk mislukte vernieuwing door de rapporteigenaar werd gemeld.
Maar wat moet u doen als uw database-interface een geplande push van de gegevens niet toestaat? In dat geval bent u verplicht de push of data-handleiding te doen. Je moet ook een centrale opslagruimte creëren.
Bij voorkeur zijn twee medewerkers, de downloadmanagers, verantwoordelijk voor het vernieuwen van de gegevens volgens een afgesproken schema. Natuurlijk mogen positie en tafel nooit worden veranderd. Alle Power BI-modellen zijn verbonden met die set tabellen en verwachten exacte namen en tabelstructuren. Deze opstelling brengt u zo dicht mogelijk bij het automatisch push- en refresh-scenario.
In het handmatig gepushte tabelscenario kunt u nog steeds de geplande vernieuwing uitvoeren vanuit de Power BI-service, maar ik zou dit niet aanraden. De geplande vernieuwing kan mislukken als u vertraging heeft en u nog steeds bezig bent met het pushen van de tafels. Als vuistregel zou ik aanraden dat als u een handmatige actie moet uitvoeren in een vernieuwingscyclus, u het beste de volledige cyclus handmatig kunt uitvoeren.
In beide scenario’s is het duidelijk dat de gedownloade bestanden alleen als tussentabellen mogen worden gebruikt. Als Power BI-dashboards aan de tabellen zijn gekoppeld, mag niemand – zelfs de downloadmanager – wijzigingen aanbrengen in de gegevens in de tabel, anders kunnen de dashboards in uw BI-modellen mislukken of erger nog, de verkeerde resultaten weergeven. Houd er ook rekening mee dat u mogelijk veel gegevens van achter het beschermde gebied van de database exporteert naar een meer open bedrijfsomgeving. In beide gevallen moet u veiligheidsmaatregelen overwegen.
Laten we nu eens kijken naar uw opties als u transformaties op de vereiste gegevens moet uitvoeren. Zoals ik in mijn vorige blog al zei, is het handmatig toevoegen van transformaties een slechte gewoonte. Je hebt dus nog de volgende opties.

Ik begin met de optie die je nooit moet gebruiken. Maak geen transformaties op de tussentafel. Na elke push wordt het oude bestand met de transformatie overschreven en moet u de transformaties steeds opnieuw uitvoeren. Dat betekent handwerk en daarmee mogelijke fouten. Zoals eerder gezegd, wil je geen wijzigingen in de tussenbestanden. De posities die overblijven om de transformaties uit te voeren bevinden zich op het begin- en eindpunt van de cyclus.
Ofwel voer je transformaties uit in de hostdatabase, ofwel met Power Query in het Power BI-model, ofwel gebruik je Dataflows. Een combinatie van deze opties is ook mogelijk. Ik zou aanraden om de databasesjabloon te gebruiken om een basistabel te maken, bijvoorbeeld door (sleutel)kolommen toe te voegen, wat rudimentaire filtering enz. en Power Query te gebruiken voor de meer geavanceerde transformaties.
De meeste reguliere zakelijke gebruikers hebben in het beste geval toestemming om de push-sjabloon aan te passen. Zoals gezegd is er niets mis met het toevoegen van sleutelkolommen en het maken van een push-schema. Ik verzoek u dringend dit te doen. Het maakt uw (zakelijke) leven een stuk eenvoudiger.
Maar als je complexere transformaties moet doen, kun je dit het beste in Power Query doen op het eindpunt van de cyclus. Voordat u met de transformaties begint, zijn er enkele overwegingen. Bijvoorbeeld in de manier waarop u de genormaliseerde tabel wilt gebruiken in uw Power BI-modellen. Als u transformaties voor slechts één Power BI-model maakt, kunt u in dat model een script maken. Maar wat als je die transformatie in meerdere modellen wilt gebruiken? U maakt (of kopieert) het Power Query-script voor elk model. Dit scenario kent zijn valkuilen, aangezien u meerdere scripts moet onderhouden. Dus als u een genormaliseerde tabel in verschillende sets Power BI-modellen wilt gebruiken, is DataFlows de juiste keuze.
DataFlows is een functie in Power BI Service, waarmee u een tabel opslaat met behulp van een Power Query M-taalscript en die tabel opnieuw gebruikt in tal van Power BI-modellen. Kortom, u sleept het M-taalscript uit uw model en gebruikt dat script om een tabel in de cloud te maken. Het werkt zo.

Houd er rekening mee dat DataFlows zijn eigen geplande vernieuwing en zijn eigen gateway gebruikt. Als u gegevens volgens dit scenario vernieuwt, moet u er rekening mee houden dat u drie verschillende tijdstippen krijgt. Eerst het pushen van de tabellen in het tussenbestand, daarna het vernieuwen van DataFlows met de tussentabellen en tenslotte het vernieuwen van het model op de DataFlows-tabellen.
In mijn volgende blog wil ik meer schrijven over DataFlows, om je meer inzicht te geven in het gebruik van deze functie.


